
Good code bad code 정리 - 4장: 오류
오류가 발생하는 건 불가피한 일이다. 아무리 애를 써도 오류가 나지 않는 코드를 짜기란 불가능하다. 따라서 오류 처리를 신중하게 생각하고 견고하고 신뢰성 높은 코드를 작성하는 것은 매우 중요하다. 적절하지 않은 오류 처리는 서비스에 큰 영향을 미치고 금전적 피해까지 초래할 수 있기 때문에 각별히 주의해야 한다.
복구 가능성
오류는 크게 두 가지로 나뉜다.
- 복구 가능한 오류: 치명적이지 않으며 사용자는 알아채지 못하도록 처리할 수 있는 오류
- 사용자의 잘못된 입력
- 네트워크 오류
- 중요하지 않은 작업 오류. 예를 들어 통계 기록이나 로깅 오류
- 복구할 수 없는 오류: 발생한 오류가 시스템이 복구할 수 있는 합리적 방법이 없는 오류. 프로그래밍 오류인 경우가 많음
- 코드 실행에 필요한 리소스가 없는 경우
- 코드가 잘못 호출된 경우 (잘못된 파라미터로 호출, 필요한 초기화를 진행하지 않은 경우 등)
복구할 수 없는 오류가 발생한 경우 이는 조용히 넘어가서는 안된다. 최대한 신속하고 요란하게 처리되어야 더 큰 문제를 방지할 수 있다.
그렇다면 복구 가능 여부는 어떻게 알 수 있을까? 보통 이는 함수를 호출하는 쪽에서 판단이 가능하다. 함수를 선언하는 쪽에서 사용될 부분의 코드까지 신경쓰며 구현하는 것은 추상화에 어긋나며 좋지 못한 코드가 된다.
- 함수가 어디서 호출될지, 호출 시 사용되는 값이 어디서 오는지 정확히 알 수 없거나,
- 코드가 미래에 재사용될 가능성이 희박하다면 에러 복구 가능 여부는 호출부에서 처리한다고 가정하는 것이 타당하다. 하지만 그렇다고해서 많은 부분을 호출부에만 기대해서도 안된다. 호출부는 처리해야 할 에러가 있는지도 모르고 있을 수 있다.
호출부가 오류에 대해 인지하도록 하기
호출부는 자신이 이용하는 함수 내부에 대해 자세히 모를 가능성이 농후하다. 예를 들어 전화번호 파싱 클래스를 이용한다고 했을 때 호출부를 작성한 개발자는 전화번호 파싱에 복잡한 로직이 사용된다는 사실을 모를 수 있다. 그래서 에러가 발생할 거라는 예상은 전혀 하지 못한채 처리 코드를 작성하지 않는 결과로 이어질 수 있다.
견고성 vs 실패
에러 처리는 항상 두 가지 시나리오 중 하나를 선택해야 한다. 에러가 발생해도 프로그램을 종료시키지 않고 계속해서 실행되도록 하여 견고성을 챙길지, 아니면 실패를 전파시켜 이상한 결과를 초래하지 않도록 할 것인지 선택해야 한다. 견고성은 중요하지만 많은 경우에 실패를 간과하지 않는 방식이 더 타당하다.
Failing fast - 빠르게 실패하기
오류는 발생했을 때 최대한 빨리 처리되어야 한다. 이는 Failing fast, 신속하게 실패하기 라고 불린다. 복구할 수 있는 오류의 경우 호출부가 에러 처리할 기회를 제공하고, 복구할 수 없는 에러의 경우 개발자가 문제를 빠르게 확인할 수 있어야 한다.
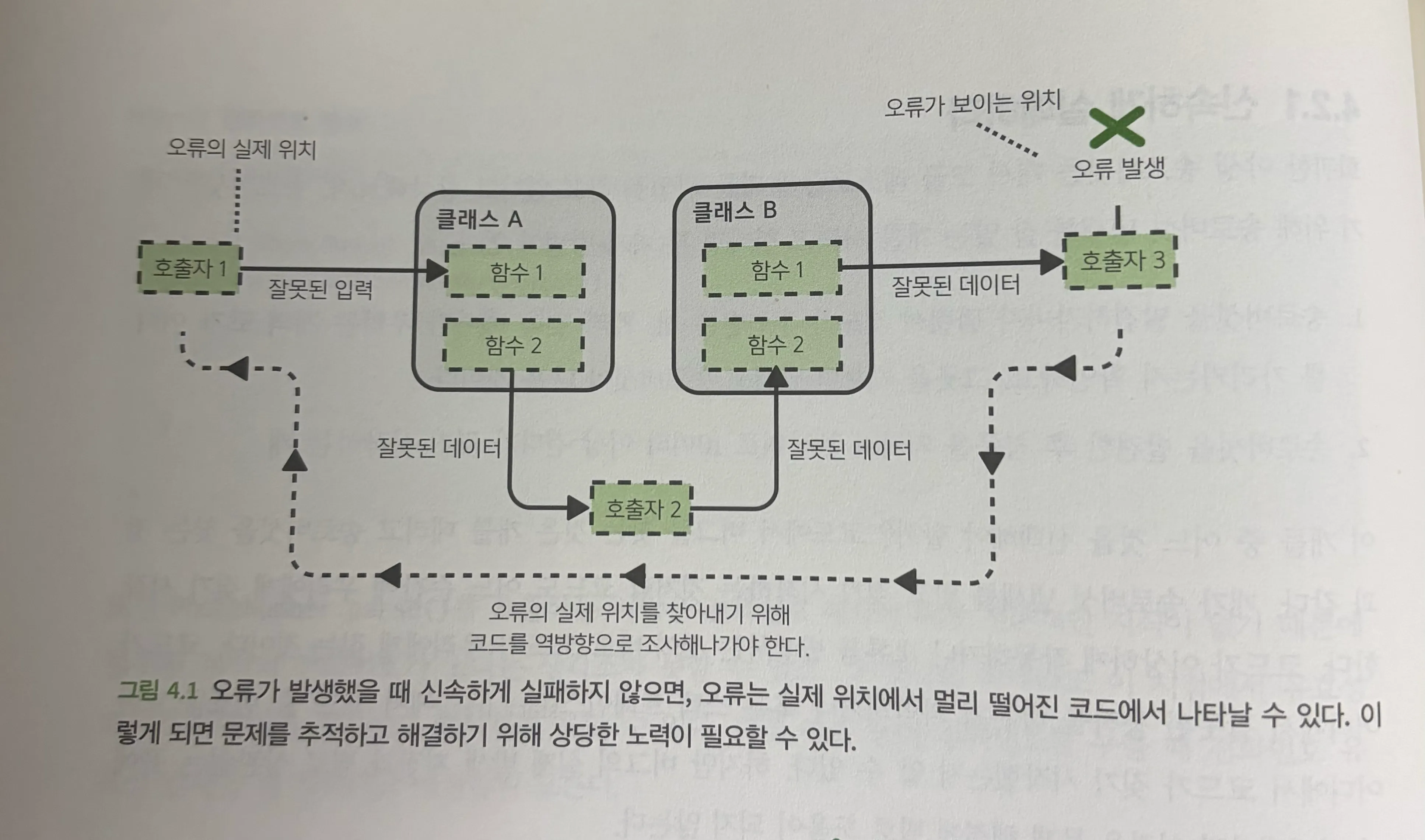
에러가 최초 발원지에서 멀리 떨어진 곳에서 발견되면 원인을 파악하는데 더 오랜 시간이 걸릴 것이다. 또는 잘못된 데이터가 데이터베이스에 저장되고 누구도 값이 이상함을 인지 못하다가 몇 달 뒤 버그를 확인할지도 모른다.
Failing loudly - 요란하게 실패하기
에러가 있다는 사실을 알지 못한다면 고칠수도 없다. 가장 확실한 방법을 에러를 발생시켜 프로그램을 중단시키는 것이다. 이는 견고함에 반대되는 동작이다. 요란한 에러는 개발 기간에도 포착되기 쉽다. 또한 에러의 발생 위치를 파악하는 것도 쉽다는 게 장점이다.
하지만 한 번의 개별 요청으로 인한 에러로 전체 프로그램을 중지 시키는 것 또한 비효율적이다. 둘 사이에서 균형을 맞추는 것이 중요하다. 절충안으로 저자가 추천하는 방식은 에러가 발생하는 경우 상세 오류 정보와 함께 로그를 남기고, 에러 발생률이 높아진다면 개발자에게 알림 메세지를 보내는 것이다. 에러 로그만 남기는 것은 부지런한 개발자가 아니면 확인이 쉽지 않다.
오류를 숨기지 않기
오류를 숨기고 조용히 넘어가면 로직이 훨씬 단순해진다. 개발자는 그 유혹에 가끔 넘어간다. 이렇게 하면 지금 당장은 편해질지라도 나비효과처럼 더 큰 문제의 원인이 될 수 있다. 오류를 조용히 넘어가는 경우 호출부에서는 의도한 대로 동작이 이루어졌다고 생각할 것이며 작성한 개발자 입장에서는 에러가 발생했다는 사실을 알 수 없으니 고칠 수도 없다.
다음은 오류를 알리는 다양한 방법들이다.
기본값 반환
에러가 발생하고 요청받은 값을 줄 수 없을 때 정해진 기본값을 반환하는 방식이다. 하지만 이 또한 에러가 발생했다는 사실을 숨기고 있다. 에러를 숨기는 것 보다는 나을 수 있지만 궁극적인 해결책으로는 맞지 않다. 예를 들어 계좌 잔액을 조회하는 API가 순간 네트워크 오류로 값을 읽지 못해 기본값 0을 반환하면, 본인 계좌 잔액이 0원인 걸 보고 깜짝 놀라는 사고가 발생할 수 있다. 차라리 에러를 발생시켜 ‘지금은 조회를 할 수 없습니다’라는 메세지를 보여주는 것이 타당하다.
널 객체 패턴
이 또한 기본값 반환과 비슷하다. 에러가 났을 때 null 객체를 반환하면 에러가 발생해 null을 주는 것인지 데이터가 없어서 null을 주는 건지 모호할 때가 있다. 주문 리스트를 조회했는데 에러가 발생해 빈 배열을 준다면 문제가 될 것이다.
아무것도 하지 않음
에러가 발생했을 때 아무것도 하지 않을 수도 있다. 호출하는 쪽에서는 당연히 지시한 동작이 발생했을 거라고 생각하기 때문에 버그가 발생할 가능성이 높다.
class InvoiceSender {
emailInvoice(emailAddress: string, invoice: Invoice) {
try {
sendEmail(emailAddress, invoice)
} catch (e) {
// do nothing
}
}
}catch 문에서 에러를 로깅하는 코드를 추가하면 현재 상태보다는 나아지지만 여전히 호출부에서는 에러가 발생한 사실을 알 수 없다는 문제가 남아있다.
오류 전달 방법
오류가 발생하면 오류를 처리할 수 있는 상위 계층으로 전파시켜야 한다. 오류를 전달하는 방법은 크게 두 가지로 나뉜다.
- 명시적 방법: 코드를 호출한 쪽에서 에러가 발생할 수 있음을 인지할 수 밖에 없도록 한다.
- 암시적 방법: 코드 호출부에 에러를 알리지만, 호출하는 쪽에서 오류를 신경 쓰지 않아도 되는 방식이다. 문서나 주석을 통해서 알 수 있는 경우도 있다. 문서에도 관련 내용이 없는 것은 숨겨진 세부 조항이라고 볼 수 있다.
| 명시적 오류 전달 | 암시적 오류 전달 | |
|---|---|---|
| 코드 계약에서의 위치 | 명확한 부분 | 세부 조항 혹은 아예 없음 |
| 호출부에서 오류 발생 가능성에 대한 인지 | O | 알 수도 있고 모를 수도 있음 |
| 기법의 예 | 검사 예외 널 반환 유형 옵셔널 반환 유형 리절트 반환 유형 아웃컴 반환 유형 스위프트 오류 | 비검사 예외 매직값 반환 프로미스 또는 퓨처 어서션, 체크 패닉 |
예외
많은 프로그래밍 언어는 예외라는 개념을 가진다. 예외는 예외를 처리하는 코드를 만날 때 까지 콜 스택을 거슬러 올라간다. 자바는 ‘검사 예외’와 ‘비검사 예외’로 예외의 개념이 두 가지이다. 보통의 다른 언어는 비검사 예외만 가지고 있다. 기본 예외 클래스를 확장해 상황에 맞는 구체적 예외 클래스를 만들어서 사용하면 좋다.
명시적: 검사 예외
자바의 검사 예외를 사용하면 호출부에서 예외 처리하거나 해당 예외 발생을 선언하지 않는 경우 컴파일 에러가 발생한다. 이는 명시적 에러 전달 기법에 속한다.
암시적: 비검사 예외
비검사 예외를 사용하면 함수의 사용부에서 예외가 발생할 수 있다는 사실을 실행하기전까지 알 수 없다. 문서화를 하더라도 코드 조약의 세부 사항에 속하게 되며 호출부에서 이를 인지하리라는 보장이 없기 때문에 암시적 전달 기법에 속한다.
명시적: 널 반환
사용 중인 언어가 널을 지원하는 경우 연산이 불가능한 경우 널을 반환하면 호출부에서 널이 반환될 수 있음을 강제적으로 인지하고 처리할 수 밖에 없다.
function getSquareRoot(value: number) {
if (value < 0) {
return null;
}
return Math.sqrt(value);
}이제 getSquareRoot의 사용부에서는 널 값을 처리하는 함수를 작성할 수 밖에 없다.
명시적: Result 반환 유형
널 값을 반환할 때의 문제점은 오류 정보를 전달할 수 없다는 점이다. Result 유형은 언어 차원애서 지원하는 언어도 있고 만약 지원되지 않더라도 직접 만들어서 사용할 수 있다. Swift, Rust 등의 언어는 result 유형을 지원한다. 사용하는 언어에서 지원되지 않으면 조금 귀찮아지는 방식이다.
class Result<V> {
private value;
private error;
constructor(value: V, error?: Error) {
this.value = value;
this.error = error;
}
// hasError, getValue 등..
}실제 Result 유형은 이보다 더 정교하다. 그리고 이전에 이런 방식을 접해보지 않은 개발자가 이런 코드를 만났을 때, getValue를 호출하기 전에 hasError를 호출하지 않으면 무용지물이다.
typescript에도 result 타입을 사용하도록 도와주는 라이브러리들이 있다. 가장 보편적으로 사용되는 건 neverthrow인 것 같고 typescript-result라는 패키지도 라이브러리 크기가 아주 작고 가벼워 부담 없이 쓸 수 있어보였다.
명시적: 아웃컴 반환 유형
무언가를 수행하고 값을 반환하지 않는 함수가 있는데 여기서 오류가 발생할 수 있고, 이것을 알리고자 한다면 값을 반환하도록 수정하는 것이 방법이 될 수 있다.
function sendMessage(channel: string, message: string) {
if (channel.isopen()) {
channel.send(message);
return true;
}
return false;
}하지만 호출부에서 이를 의도치않게 무시해버릴 수도 있다.
function sayHello(channel: string) {
sendMessage(channel, "hello");
ui.setOutput("Sent hello");
}Java에는 이를 무시할 수 없도록 하는 어노테이션이 있다. @CheckReturnValue를 추가하면 컴파일에러가 발생해 호출부에서 반환값을 확인하지 않을 수 없도록 한다.
암시적: 프로미스 / 퓨처
비동기 코드를 작성하면 프로미스를 반환하게 된다. 프로미스를 사용하는 경우 then과 catch를 사용하지 않으면 오류를 포착할 수 없기 떄문에 이는 암시적 오류 전달 방식으로 분류된다. result 패턴과 결합해 프로미스를 사용하면 명시적 오류 전달을 할 수 있다. 하지만 코드가 복잡해진다는 단점이 있다. 하지만 이 또한 라이브러리를 사용하면 좀 더 간편하게 패턴을 도입할 수 있다. 아래는 neverthrow를 이용한 프로미스에 리절트 패턴을 입힌 예시 코드이다.
import { errAsync, ResultAsync, andThen } from "neverthrow";
import { insertIntoDb } from "imaginary-database";
function addUserToDatabase(user: User): ResultAsync<User, Error> {
if (user.name.length < 3) {
return errAsync(new Error("Username is too short"));
}
return ResultAsync.fromPromise(
insertIntoDb(user),
() => new Error("Database error"),
);
}
const asyncRes = addUserToDatabase({ name: "Tom" });
const asyncRes2 = asyncRes
.map((user: User) => user.name)
.andThen((name) => callOtherService(name));
const res = await asyncRes;
if (res.isErr()) {
console.log("Oops fail: " + res.error.message);
} else {
console.log("Successfully inserted user " + res.value);
}리턴 타입이 Promise
암시적: 매직값 반환
magic value란 정상 값을 반환하지만 값에 특별한 의미를 부여한 값이다. 문서를 읽지 않으면 의미를 알 수 없기 때문에 암시적 방식이다.
// 입력값이 음수면 -1을 반환한다.
function getSquareRoot(value: number) {
if (value < 0) {
return -1;
}
return Math.sqrt(value);
}주석문을 읽지 않으면 -1 반환값의 의미를 알 수 없다. 매직값은 여러가지 문제를 일으킬 수 있으므로 사용하지 않는 것이 좋다.
명시적 vs 암시적 에러 처리
둘 중 어느 방식을 사용할 지는 첫째로, 팀에서 사용하는 방식을 따라야 하는 것이 가장 우선이다. 암시적 에러 처리를 선호하는 개발자들은 어차피 상위 계층으로 에러가 전파되니 개발자는 하위 계층의 더 의미있는 핵심 로직에 집중하자는 의견이다.
try {
doSomething();
} catch (e) {
// do nothing
}곳곳에 try-catch를 작성해 각 에러를 처리하는 것은 로직에 변경이 생겼을 때 번거로워지고 결국 오류를 숨기는 선택으로 이어질 지도 모른다. 하지만 저자의 의견은 그럼에도 불구하고 명시적으로 오류를 처리할 것을 추천한다. 명시적 오류 처리 방식을 사용해 호출부에서 에러를 무시할지 처리할지 선택권을 주는 것이 프로그램의 에러를 놓칠 가능성을 줄이는 방식이라고 한다. 어느 한가지 방법에 매몰되지 않고 상황에 맞는 유연한 사고를 하는 것이 더 중요할 것 같다.